Sparse Matrix-Matrix Multiplication with Tile Library¶
Warning
This document is still experimental and may be incomplete.
This feature is still experimental and need further optimization.
Suggestions and improvements are highly encouraged—please submit a PR!
Tip
It’s suggested to go through docs/deeplearning_operators/matmul.md first.
Example code can be found at examples/gemm_sp.
Structured sparsity in the NVIDIA Ampere architecture¶
Since the Ampere architecture (sm80 and above), sparsity support has been integrated into Tensor Cores. This allows a 2:4 (or 1:2 for 32-bit data types) semi-structured matrix to be compressed into its non-zero values along with associated metadata, which can then be fed into the Tensor Core. This enables up to 2x throughput compared to the equivalent dense computation.
Warning
This tutorial primarily focuses on CUDA, as this feature is not yet supported on ROCm. However, AMD provides a similar capability in the matrix cores of GPUs such as the MI300X.
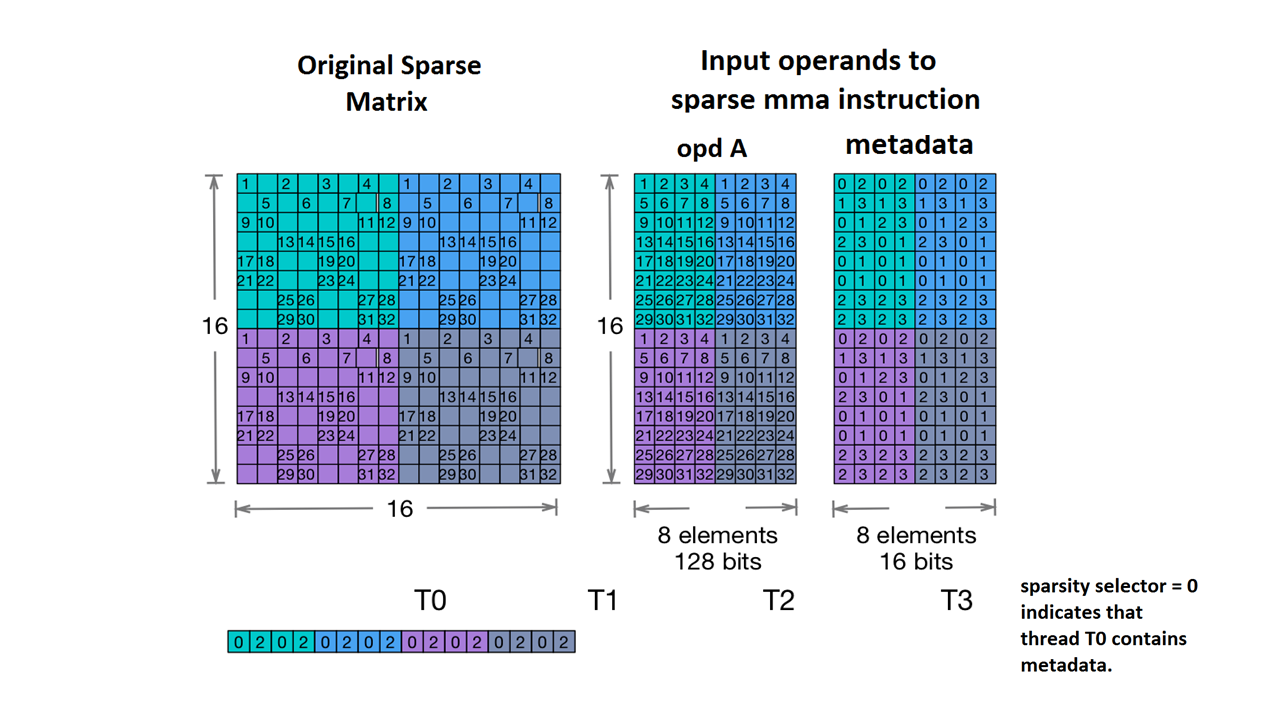
Figure: Sparse MMA storage example (from PTX doc)¶
Compress a dense tensor¶
To utilize sparse Tensor Cores, a dense tensor must first be compressed into its non-zero values along with the corresponding metadata.
Both PyTorch and vLLM use CUTLASS as their computation backend (see references here and here), leveraging CUTLASS’s built-in compressor (or reimplementing it in PyTorch).
A compressor is provided with the sparse GEMM example in examples/gemm_sp/sparse_utils.py. Pass in a dense 2:4-sparse tensor and optionally a metadata dtype to get back the compressed values and metadata:
from examples.gemm_sp.sparse_utils import compress
A_sparse, E = compress(A) # default: int16 metadata for fp16/bf16
A_sparse, E = compress(A.t().contiguous()) # compress the transposed layout
Here, A_sparse contains all the non-zero elements of A, while E stores the corresponding metadata (indexing information) required to reconstruct the original sparse pattern. The metadata uses a natural row-major layout that T.gemm_sp consumes directly — no additional layout annotation is needed.
T.gemm_sp¶
A 2:4 sparse GEMM kernel is similar to its dense counterpart, except that it also requires loading the metadata into shared memory and passing it to T.gemm_sp.
The default metadata dtype for fp16/bf16 is int16 with an E-factor of 16 (one int16 value covers 16 K-elements). For int8/float8 the default is int32 with E-factor 32.
import tilelang.language as T
from examples.gemm_sp.sparse_utils import get_e_factor
def matmul_sp(
M, N, K,
block_M, block_N, block_K,
in_dtype, accum_dtype, e_dtype,
num_stages, threads,
policy=T.GemmWarpPolicy.Square,
):
e_factor = get_e_factor(in_dtype, e_dtype)
@T.prim_func
def main(
A_sparse: T.Tensor((M, K // 2), in_dtype),
E: T.Tensor((M, K // e_factor), e_dtype),
B: T.Tensor((K, N), in_dtype),
C: T.Tensor((M, N), accum_dtype),
):
with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), threads=threads) as (bx, by):
A_shared = T.alloc_shared((block_M, block_K // 2), in_dtype)
B_shared = T.alloc_shared((block_K, block_N), in_dtype)
E_shared = T.alloc_shared((block_M, block_K // e_factor), e_dtype)
C_local = T.alloc_fragment((block_M, block_N), accum_dtype)
C_shared = T.alloc_shared((block_M, block_N), accum_dtype)
T.clear(C_local)
for k in T.Pipelined(T.ceildiv(K, block_K), num_stages=num_stages):
T.copy(A_sparse[by * block_M, k * block_K // 2], A_shared)
T.copy(E[by * block_M, k * block_K // e_factor], E_shared)
T.copy(B[k * block_K, bx * block_N], B_shared)
T.gemm_sp(A_shared, E_shared, B_shared, C_local,
transpose_A=False, transpose_E=False, transpose_B=False,
policy=policy)
T.copy(C_local, C_shared)
T.copy(C_shared, C[by * block_M, bx * block_N])
return main